Getting started
Install TRL withuv or pip. Choose one of the options below based on your setup.
Training models with TRL and logging traces/completions using Weave
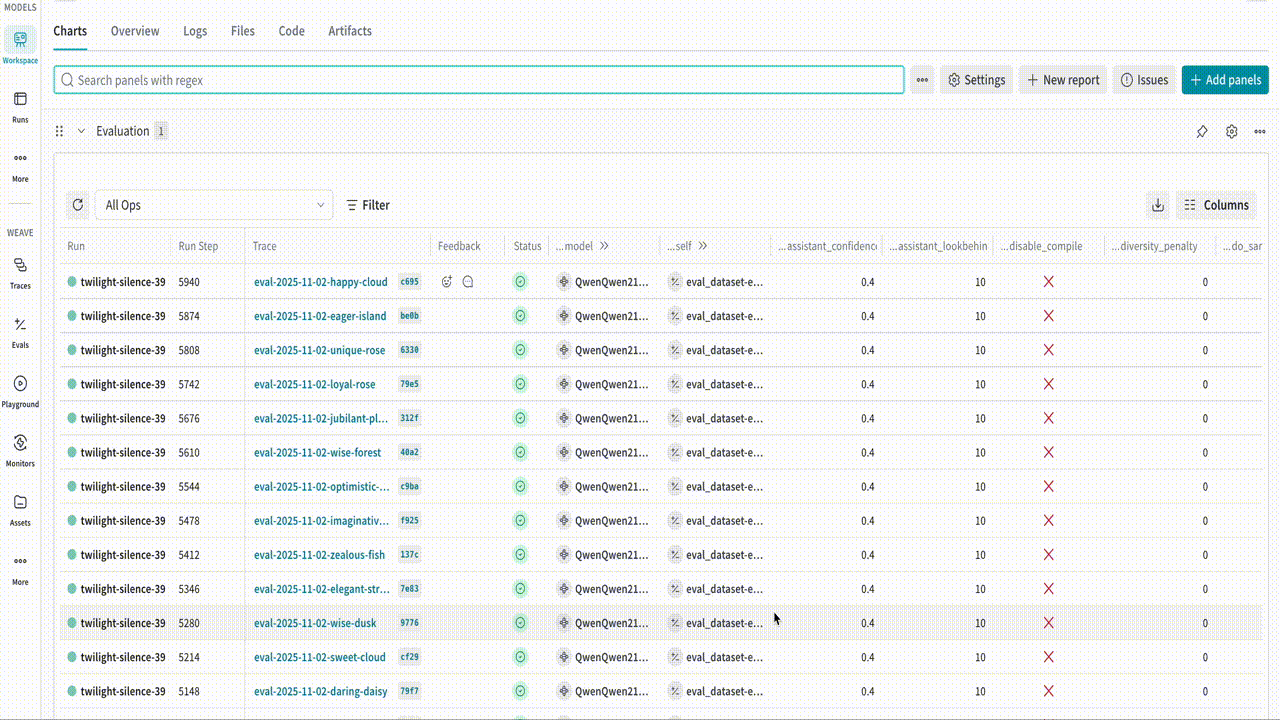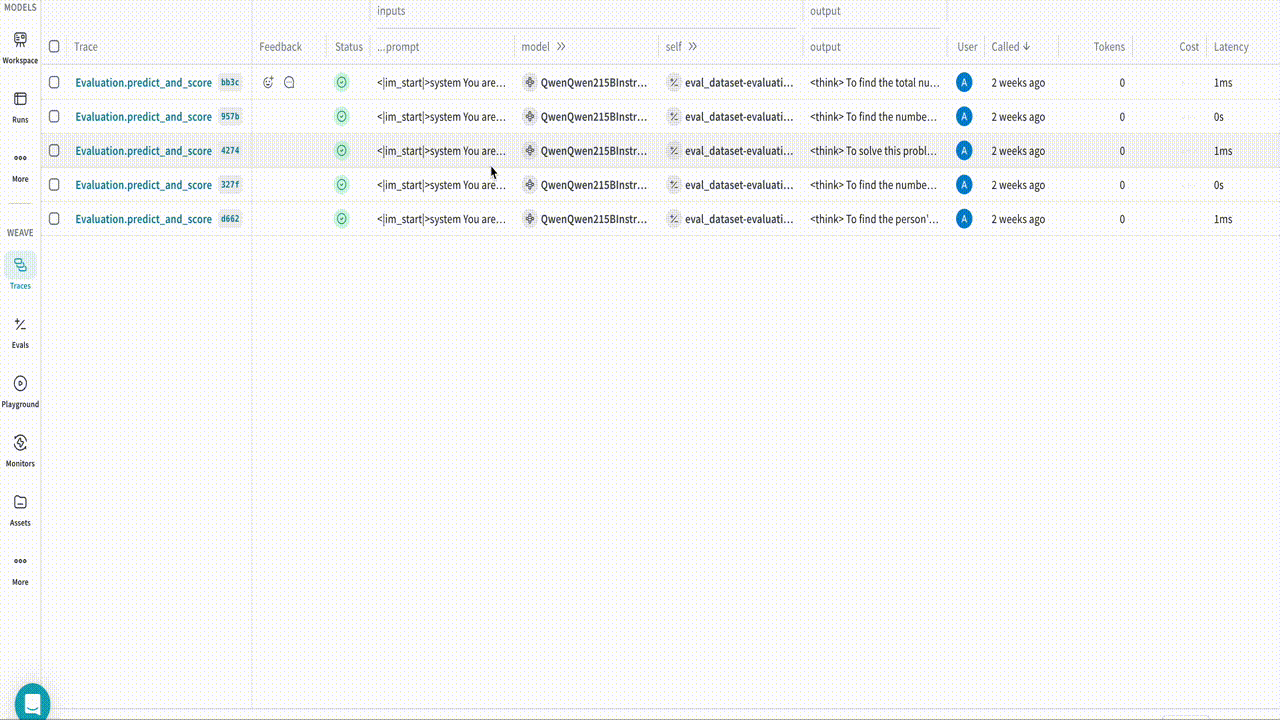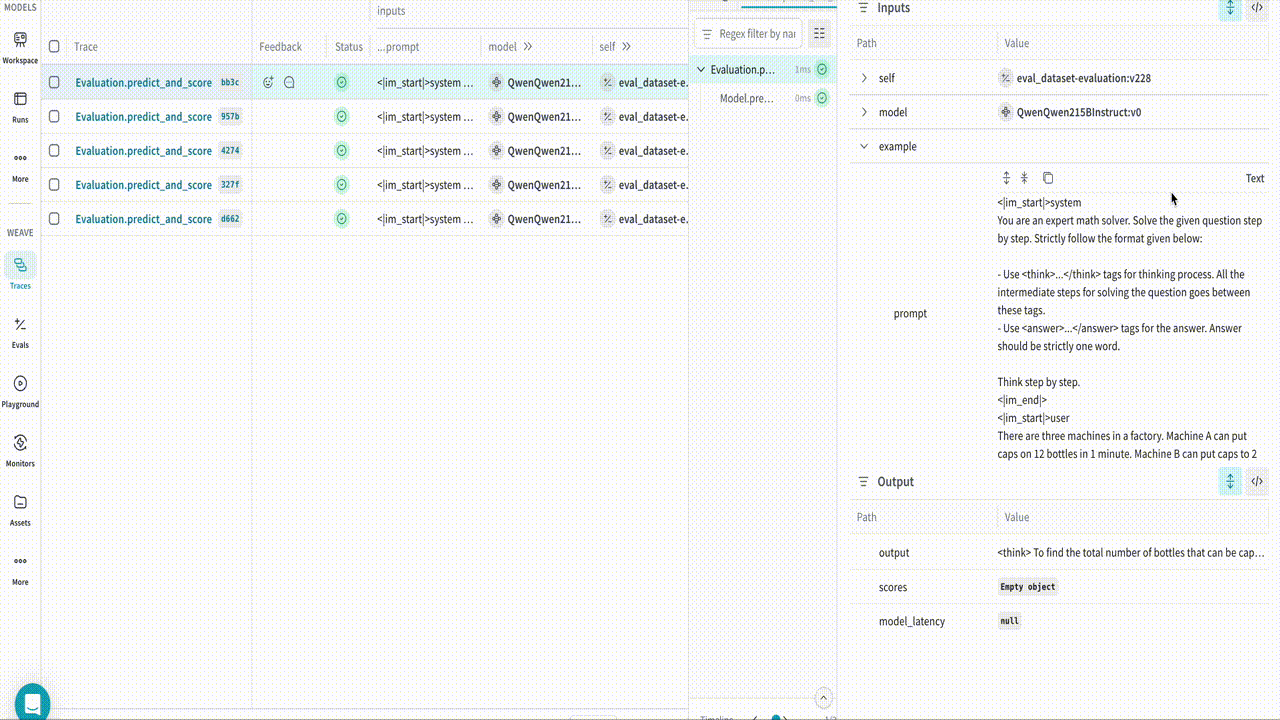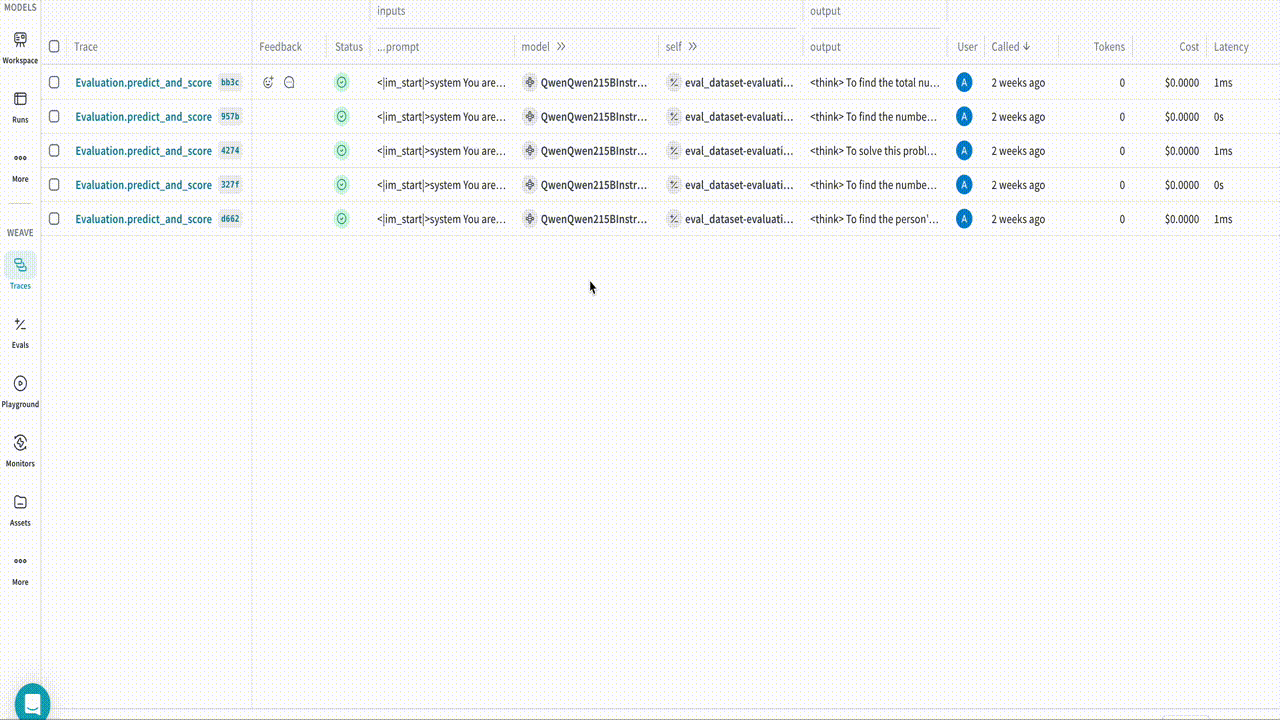
Once you have installed the necessary libraries, you can use the built-in WeaveCallback in TRL to log traces and completions at each evaluation step. The callback logs data during evaluation phases, so you need to pass an evaluation set to the trainer object. The following example script demonstrates how to run an evaluation with TRL and log the results to Weave when training a model with the GRPOTrainer. Run the example and inspect the results in Weave:Resources
Here are some resources you can use to learn how to integrate Weave with different workflows:- WeaveCallback documentation
- Curated examples that show how to use Weave with TRL for different algorithms.